近年来,美国在AI决策认知领域同样积极展开尝试,典型的空中博弈比赛当属2019年开始举办的“AlphaDogfight”,旨在演练执行可视范围内的模拟空战 AI 算法,促进人机协同作战。值得一提的是,在2020年的总决赛中,苍鹭系统公司的 AI 算法在虚拟空战中以压倒性优势(5:0)击败了人类顶级飞行员,让人们看见人机共生全新前景的同时,也极大地提高了作战人员对自主作战技术的信任度。
2021 首届全国空中智能博弈大赛由中国指挥与控制学会主办,中国航空工业集团沈阳飞机设计研究所等6家单位承办。赛事以异构、全透明态势空战为想定,主要考验 AI 在编队行动、协同制导、目标打击等方面的决策能力。
和“AlphaDogfight”的不同之处在于,“AlphaDogfight”是AI智能体和F-16飞行员在有战争迷雾的模拟环境中进行一对一的空中格斗;本次大赛则是以类“忠诚僚机”体系进行战术小队的对抗,即红蓝双方各为”一架有人机带四架无人机“。前者关注“装备级”、“动作级”博弈智能,后者关注“编队级”、“协作式”智能。
采用强化学习+部分策略规则融合的方式,利用AI智能作战专业领域的知识,依托多智能体协同决策平台Nash-Studio和多智能体强化学习框架Nash-Zero,在对战模拟环境中进行高效推演训练,探索并不断调整现有作战策略,输出高质量的、最优的、可验证的方案来辅助合理决策部署,成为制胜关键。
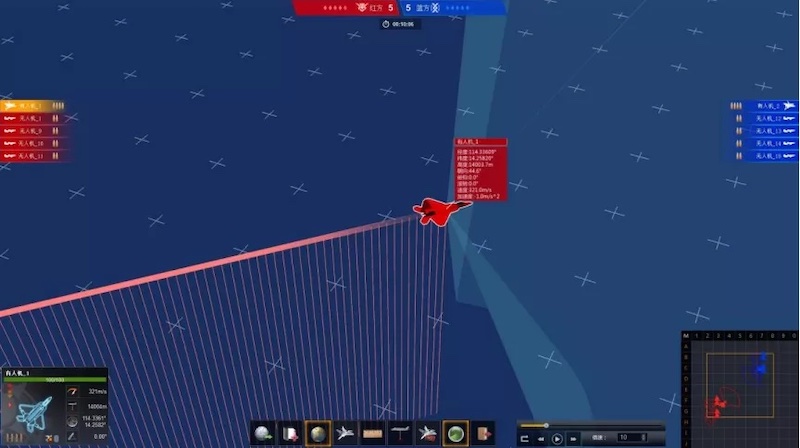
通过强化学习的自博弈、规则策略对抗、人机对抗等多种智能对抗博弈方式生成的大量回放数据,利用Nash-Studio平台辅助复盘分析,充分挖掘潜在的策略,如在对飞机战斗梯队、火控雷达制导、火力协同打击、导弹最优躲避等方面挖掘到了高质量的策略,并利用机器学习、深度强化学习等智能算法对策略进行整体融合。同时,针对敌方导弹的近距法向过载能力,使用深度强化学习算法针对导弹锁定场景进行局部躲避训练,利用智能体精准有效操作将躲避成功几率提升至最大。
此外,在训练智能体过程中,由于比赛时间间隔短,而空战对抗复杂,尽管利用了Nash-Zero框架中的并行、分布式等方式训练,还是很难在短时间内训练出最优的智能体。然而战队探索发现,通过将机动决策和攻击决策进行分层学习,可降低了强化学习的智能体学习难度,提升强化学习的收敛速度。多方发力,解决了作战规则表达与指挥决策智能优化问题。

工业4.0创新平台 版权所有 All Rights Reserved, Copyright© 2013- 京ICP备14017844号-3

评论