导读:传统的数据分析方法需要完美的结构化数据,新的数据分析方法则采用了机器学习在原始数据直接处理,这是GE Digital数据科学家孜孜以求的目标。本文作为数字孪生制造之八,主要介绍GE的数据驱动策略。
虽然GE提出了“工业互联网”(Industrial Internet),但是它很快发现数字孪生体才可以称得上工业互联网的核心,大量的核心竞争力必须围绕数字孪生体构建,其中,在数字孪生基础设施上,可以利用机器学习等人工智能工具,提升数据分析的质量。
GE Digital的数据科学家Sarah Lukens对此做了完整的介绍,推荐数字孪生体联盟成员参加数字孪生体课堂对应在线课程,学习全部演讲内容。

Sarah Lukens一直学习计算科学,博士毕业后还在高校还工作了一段时间。2014年10月加入Meridium,负责设备健康管理工作,2016年Meridium被GE收购后,成为GE Digital的数据科学家,主要负责资产性能管理认知分析工作。
通常情况下,工业数据有三大挑战:数据可信度、数据应用和数据标准化。
工业4.0研究院发现,国内大部分处理工业数据的做法跟消费数据类似,那就是想法子“标准化”,这是一条可行的技术路径,国际标准有ISO 14224,SMRP,它们对工业数据如何处理提出了完整系统的指导。
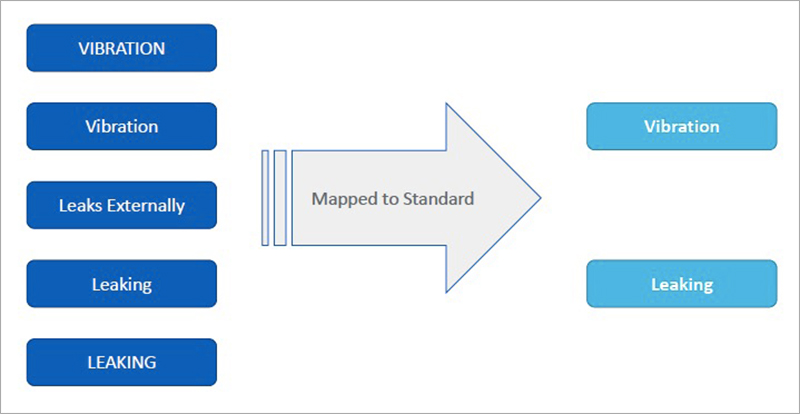
但是,仅仅依赖于标准化的传统方法显然不够,GE Digital的数据科学家应用数字孪生基础设施,可以做系统工程分析,即便数据有大量缺失,也可以利用NLP等方法来弥补。
这种方法跟DARPA解决数据分析缺失的方案类似,那就是从原始数据(Raw Data)入手,而不是经过必须的数据清理和整理,当然,这样做带来新的工作内容——开发处理原始数据的工具。
数字孪生制造系列文章以介绍为主,不详细讲解技术细节,有兴趣的行业人士可以自行阅读演讲稿。
Sarah Lukens在演讲稿最后,讲解了数据驱动策略的核心——商业模式。
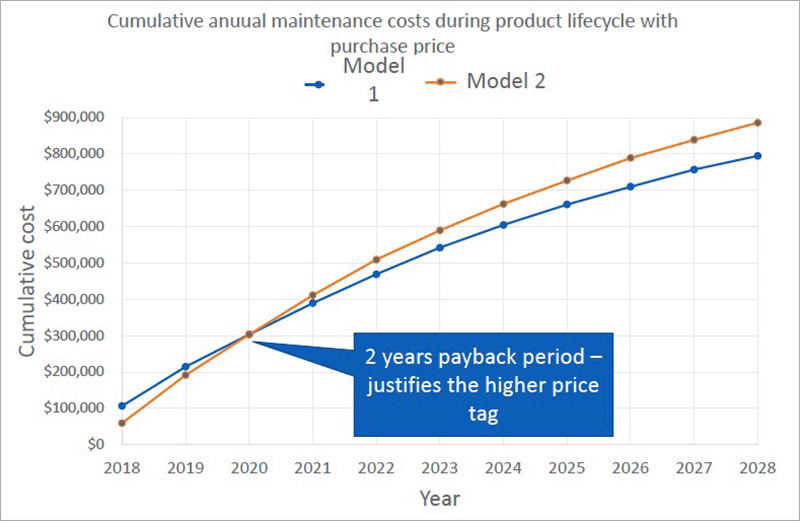
采用不同的运维模式,那么就可以给客户提供基于不同模式的解决方案,包括收费方法。
演讲稿中,Sarah Lukens分析了Model 1和Model 2两种方法的累计成本,初期(2018年)Model 1成本高于Model 2,但只到第二年两者成本类似,以后每年设备资产性能解决方案的成本逐年比Model 2要低。
回到Sarah Lukens这位数据科学家,她最近一些年非常活跃,撰写了不少机器学习驱动的数据分析方法,这些论文也发布到数字孪生体课程对应课程了。
如果对本文所讲内容感兴趣,大家可以到数字孪生体课堂学习对应课程(本课程链接:https://uni.innodigital.cn/course/17,或点击阅读原文),数字孪生制造系列文章对应的演讲稿都会发布到课程页面上去。

工业4.0创新平台 版权所有 All Rights Reserved, Copyright© 2013- 京ICP备14017844号-3

评论