ChatGPT和GPT-4的出现以大语言模型(LLM)吸引了世界,在问答、总结和内容生成方面表现出卓越的性能。
为了帮助数字孪生体联盟了解行业大模型的研发流程和方法,特编译AviationGPT相关内容,供大家参考研究。如果成员有相关疑问,可以在数字孪生体联盟官方微信群交流讨论。
航空业的特点是大量复杂、非结构化的文本数据,充满了技术术语和专业术语。
此外,模型构建的标签数据在这个领域很少,导致航空文本数据的使用率低。LLM的出现为改变这种情况提供了一个机会,但缺乏专门为航空领域设计的LLM。

为了弥补这一差距,可以使用AviationGPT,它建立在开源的LLaMA-2和Mistral架构上,并不断接受大量精心策划的航空数据集的培训。
实验结果显示,AviationGPT为用户提供了多种优势,包括解决各种自然语言处理(NLP)问题的多功能性(例如,问答、总结、文档编写、信息提取、报告查询、数据清理和交互式数据探索)。
它还在航空领域内提供准确和与上下文相关的响应,并显著提高性能(例如,在测试案例中,性能提升超过40%)。
有了AviationGPT,航空业可以更好地解决更复杂的研究问题,并提高国家空域系统(NAS)运营的效率和安全性。
研发人员选择了两组开源LLM来开发AviationGPT。第一个系列LLaMA-2包括三个基本型号(7B、13B、70B),而第二个系列Mistral迄今为止只发布了7B型号。
所有基本LLM都具有仅解码器的架构,并使用自回归语言建模方法。
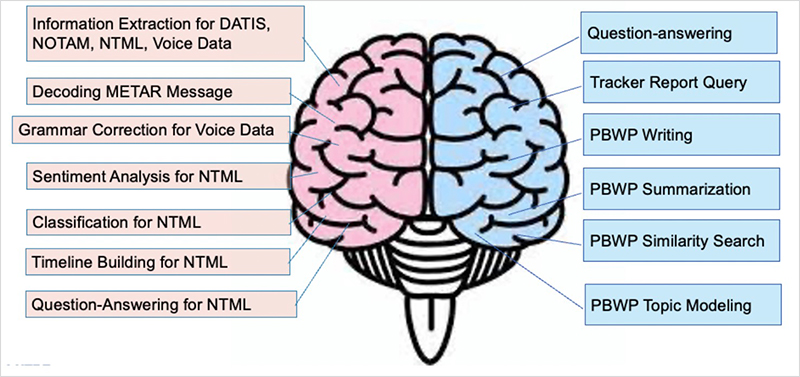
AviationGPT训练采用了经典的两阶段领域特定训练框架,它由预训练阶段和指令微调阶段组成。
在第一阶段,使用精心策划的未标记航空文本数据集进行持续的预训练。
在第二阶段,在精心策划的指令调优数据集上执行指令调优。

两个阶段都使用QLoRA方法来降低训练成本。
阶段1的计算量比阶段2的计算量更大。例如,在阶段1中训练LLaMA2-70B大约需要48小时,而阶段2需要大约1.5小时。
根据AviationGPT训练,编译了两个数据集。无监督预训练数据集是从四个来源收集的。
首先,从美国国家航空航天局(NASA)和美国联邦航空管理局(FAA)的网站上获得了52本航空相关书籍。
其次,使用了技术报告数据集,这些数据集为赞助商记录了MITRE的航空研究,从2017年到2023年,收集了大约750份报告。
第三个组成部分来自MITRE的基于产品的工作计划(PBWP),该计划概述了赞助商制定的航空研究要求。
与Tracker来源一样,从2017年到2023年收集了大约1400份文件。
最后,提供了介绍航空文本数据库的信息(例如,空中任务通知[NOAM]、数字自动终端信息服务[DATIS]、气象机场报告[METAR])。

工业4.0创新平台 版权所有 All Rights Reserved, Copyright© 2013- 京ICP备14017844号-3

评论