在《全球工业4.0研究报告(2020)》中,有一个章节为“引领数字孪生创新的中国力量”,重点谈了中国正在发生的颠覆性创新。工业4.0研究院结合到专题研究成果,把参与数字孪生体领域的力量分为仿真、连接和数据三大流派。
这个说法引起了不少行业人士关注,在数字孪生体联盟微信群中,各位专家就这个问题做了激烈讨论。
工业4.0研究院把自己定位于“数据派”,为此本人计划写几篇文章,谈谈我们的理解。

数字孪生体参考架构(DTRA)
从工业4.0研究院提出“数字孪生体参考架构”(DTRA,Digital Twin Reference Architecture)来看,自下而上分为数字孪生化(Digital Twinning)、资产化(Digital Assets)、平台化(Digital Platform)和服务化(Digital Services),俗称“四化”。
简而言之,数字孪生体参考架构自成体系,企业可以放心大胆实施数字化转型,而无需担心是否需要先建设工业互联网。
首先,目前大部分企业使用数字孪生技术限于工厂边界,大量数据交换发生在内部IT系统,跟工业互联网关系不大。当然,如果我们认为IT系统也是工业互联网的一部分,称之为数字孪生体的基础也未尝不可。

富士康公司设计的“雾小脑”设备
由于数字孪生化过程产生的数据量比较大,在目前的技术环境下,不适合使用公有云。
富士康公司遇到类似的困难,为此,它提出了一套“雾小脑”体系,避免本地数据跟云平台交互,降低了成本,提高了人工智能分析效率。
郭台铭公开讲,“因为云计算来回处理数据太慢了,所以我们就设计了一个‘雾’的概念,可以进行雾计算,‘雾小脑’。雾小脑本身数据积累的足够多,就可以产生了一个‘小脑’。”
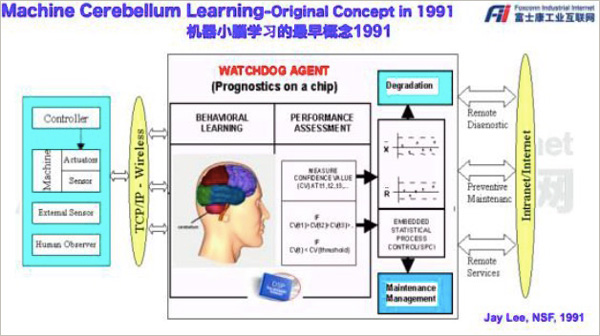
李杰在演讲中分享的“机器小脑学习”
在中国台湾鸿海公司工作的李杰副董事长引用自己在1991年的论文称早就有这样的设计,可见“雾小脑”并不等同于工业互联网。
不管怎样,至少有一个结论是成立的,在实际企业数字化转型过程中,上不上公有云不是必要条件。
其次,数字孪生体本质上是“数据驱动”(Data-Driven),相比以“网络化”或“连接”为目标的工业互联网,追求的目标不同。
既然要实现数据驱动,那么不能以信息化为手段,应该聚焦数据化,这一点在《全球工业4.0研究报告(2020)》中“数据化转型将重塑日本制造业”部分阐释得较详细。
如果仅仅是信息化的延续,那么日本就没有必要推“数据化转型”了。
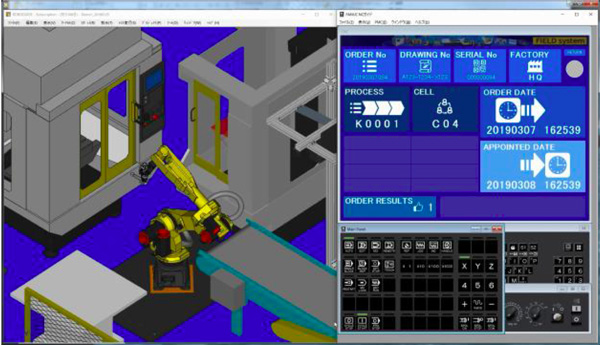
发那科与富士通基于数字孪生体数据化转型
在数字孪生体数据派认识中,数字孪生化是起点,这有点类似早期斯坦福大学李飞飞教授用大量数据研究深度学习一样,这个细分领域有大量的工作需要做,数字孪生体研究中心感觉“开源”仍然是解决办法。
部分企业通过UE 4或者其他工具给特定工厂做了一些模型,把它称之为数字孪生体,这样没有太大问题,但如果还是基于信息化的思路来做,可能达不到数据驱动的目的,至少没有释放数字孪生体的潜力。
最后,大家之所以对数字孪生体和工业互联网的关系有困惑,主要是目前连接派把数字孪生(这也是他们为什么没有加上“体”的原因之一)工具化了,通过把一个系统性概念工具化,大大压制了它的发展潜力。
有一点是肯定的,数字孪生体并不需要工业互联网概念亦可建立完整的系统。
美国、德国和日本等工业强国提及工业互联网概念的企业并不多,甚至于积极参与美国工业互联网联盟的西门子美国公司,在提及解决方案的时候,也没有提到工业互联网,反而用数字孪生体重构了原有的PLM业务。
当然,在建设数字孪生体的时候,把工业互联网元素引入亦无不可,但前提应该是成本足够低,毕竟我们的目标是为了实现数据驱动,大部分企业不需要“整合”产业链,或者跨界经营,网络化不是寻求生存空间的首要工作。
撰写本文本意是系统阐释数字孪生体研究中心看法,以便跟行业人士进行深入交流。欢迎同行人士到数字孪生体联盟微信群交流探讨。

工业4.0创新平台 版权所有 All Rights Reserved, Copyright© 2013- 京ICP备14017844号-3

评论